
Trunk-Based Development
Journaux liées à cette note :
Journal du vendredi 23 août 2024 à 12:35
Depuis des années, j'essaie de suivre avec rigueur la doctrine suivante dans les projets utilisant le workflow Trunk-Based Development.
- La branche trunk doit toujours être stable et contenir uniquement du code fonctionnel.
- Le code obsolète ou inutilisé doit être supprimé de la branche trunk.
- Aucun code commenté ne doit figurer dans la branche trunk.
- La branche trunk ne contient pas de tests qui échouent.
Pourquoi ?
- Pour éviter qu'un développeur perde du temps à essayer de faire fonctionner quelque chose qui n'est pas en état de marche.
- Pour éviter qu'un développeur refactore du code mort — j'ai observé à nouveau cela, il n'y a pas longtemps 😔. Quand le développeur fini par le découvrir, il est généralement très frustré.
- Pour éviter l'installation et la mise à jour de bibliothèques qui alourdissent inutilement le projet.
- Pour prévenir une perte de confiance dans le projet (voir l'hypothèse de la vitre brisée).
Et si j'ai besoin de ce code plus tard ?
Tout d'abord, je vous réponds "YAGNI" 🙂.
Plus sérieusement, ma réponse est que votre code ne sera pas perdu étant donné qu'il est versionné dans votre repository.
Si le code commenté est en cours de développement, alors je suggère d'extraire ce code en préparation dans une Merge Request et de la merger quand elle sera prête.
Trouvez le bon équilibre
Un morceau de code commenté ou un test qui échouent peut tout à fait rester dans trunk sur une courte période. Dans ce cas, je conseille d'ajouter en commentaire un lien vers l'issue de dette technique qui détaille l'action prévue.
Journal du mardi 20 août 2024 à 18:05
Depuis 2012, je pratique exclusivement le Git Rebase Workflow pour tous mes projets de développement.
Concrètement :
- J'utilise
git pull --rebasequand je travaille dans une branche, généralement une Pull Request ou Merge Request ; - Je pousse régulièrement des commits en "work in progress" au fil de l'avancée de mon travail dans ma branche de développement avec la commande
git commit -m "WIP"; git push; - Une fois le travail terminé, je squash mes commits à l'aide de
git rebase -i HEAD~[NUMBER OF COMMITS]; - Ensuite, je rédige un commit message qui contient la description du changement et le numéro de l'issue ou de la merge request
git commit --amend; - Enfin, j'effectue un Merge en Fast-Forward en utilisant l'interface de GitHub ou GitLab.
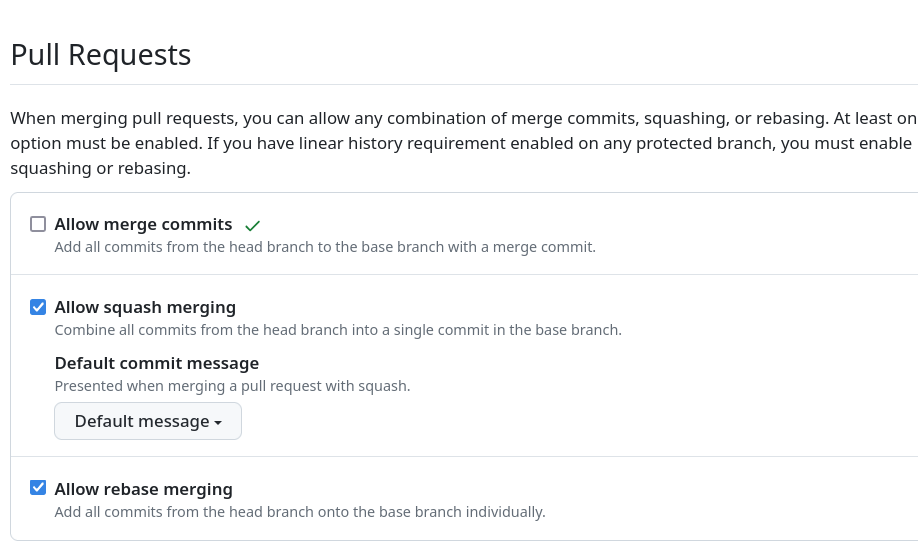
Pour cela, je paramètre GitLab de la façon suivante (navigation "Settings" => "General") :

Ou alors je paramètre GitHub de la façon suivante (navigation "Settings" => "General")
Les avantages de cette pratique
L'approche Rebase + Squash + Merge Fast-Forard permet de maintenir l'historique de changements linéaire, rendant celui-ci plus facile à lire et à comprendre.
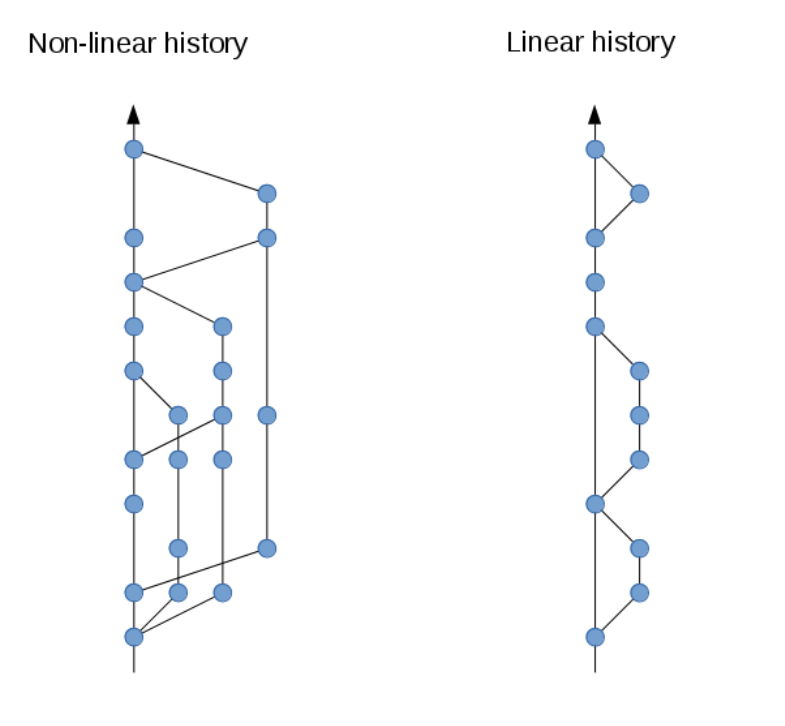
L'historique ne contient aucun commit de fusion inutile.
Cela facilite la mise en place d'Intégration Continue.
Tous les problèmes, bugs, et conflits sont traités dans les branches, dans les Merge Request et jamais dans la branche main qui se doit d'être toujours stable, ce qui améliore grandement le travail en équipe.
Ce workflow est particulièrement puissant lorsque l'historique linéaire ne contient que des commit dit "atomic", c’est-à-dire : 1 issue = 1 merge request = 1 commit. Un commit est considéré comme "atomic" lorsqu'il ne contient qu'un seul type de changement cohérent, tel qu'une correction de bug, un refactoring ou l'implémentation d'une seule fonctionnalité.
À de rares exceptions près, le code source de la branche main doit rester stable et cohérent tout au long de l'historique des commits.
Cette discipline favorise un travail collaboratif de qualité, rendant plus compréhensible l'évolution du projet.
De plus, l'atomicité des commits facilite la revue des Merge Request et permet d'éviter les Commits Cavaliers.
Généralement je couple ce Git workflow au workflow nommé Trunk-Based Development.